
스프링 입문 4. 데이터 액세스 층의 설계와 구현
26 Jan 2019 - breadkey
데이터 액세스 층과 스프링
주요 역할은 데이터 액세스 처리를 비즈니스 로직 층에서 분리하는 것이다. 데이터 액세스를 분리하지 않으면 소스코드에 로직과 데이터 액세스가 섞여 가독성이 매우 떨어지고 지저분해진다.
DAO 패턴이란?
데이터의 취득과 변경 등의 데이터 액세스 처리를 DAO라고 하는 오브젝트로 분리하는 패턴이다. 데이터 액세스 방식이 바뀌어도 DAO만 변경하면 되므로 비즈니스 로직에는 영향을 주지 않고 처리할 수 있다.
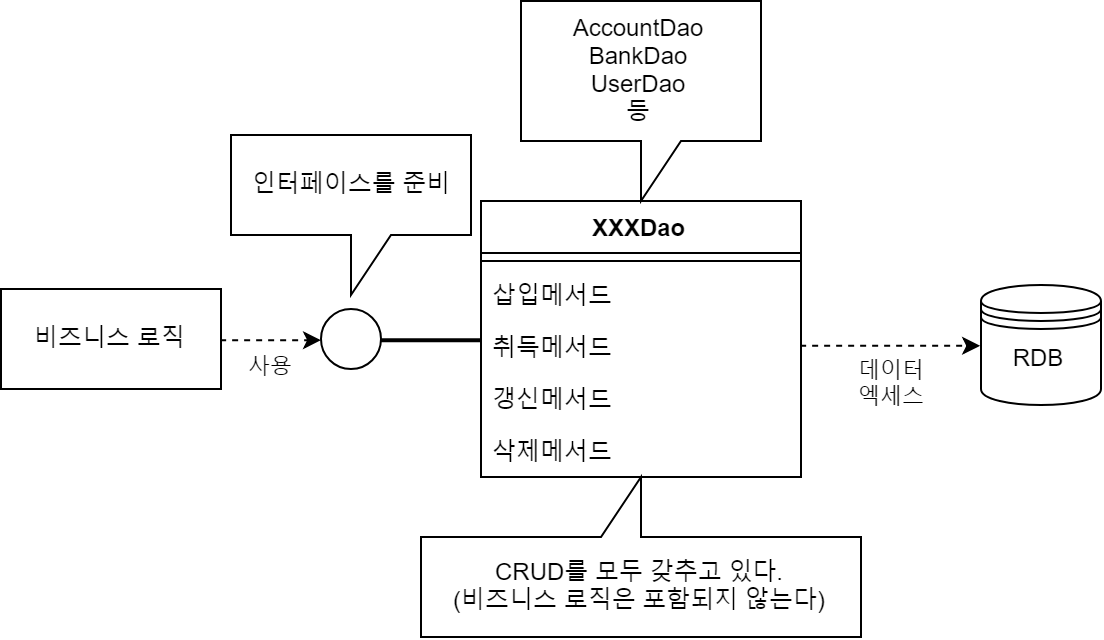
DAO 클래스는 보통 데이터베이스의 테이블별로 만들어진다. 기본적으로 테이블에 대한 단순한 CRUD를 갖춘 형태가 된다. 비즈니스 로직이 포함되지 않는 단순한 소스 코드이므로 테이블 정의 정보를 바탕으로 DAO를 자동 생성하기도 한다.
자바의 데이터 액세스 기술과 스프링의 기능
데이터 액세스 처리를 구현하는 자바 기술에는 여러 가지가 있다. JDBC를 비롯해 하이버네이트와 JPA 등 고성능 ORM 프레임워크 등이 존재한다.
스프링은 기존의 데이터 액세스 기술을 쉽게 사용하기 위한 연계 기능을 제공한다. JDBC, 하이버네이트 JPA에 대해서는 스프링에서 연계 기능을 제공하고 있고, MyBatis는 MyBatis에서 제공한다. JPA는 스프링 데이터 프로젝트의 스프링 데이터 JPA를 이용할 수도 있다.
스프링과 연계함으로써 세 가지 장점을 얻을 수 있다.
- 데이터 엑세스 처리를 간결하게 기술할 수 있다.
- 스프링이 제공하는 범용적이고 체계적인 데이터 액세스 예외를 이용할 수 있다.
- 스프링의 트랜잭션 기능을 이용할 수 있다.
범용 데이터 액세스 예외 처리
데이터 액세스 기술에 의존하지 않는 범용적인 예외 클래스군이다. 데이터 액세스 시의 에러 원인을 체게적으로 정리해서 에러의 원인별로 클래스를 만들어뒀다. 데이터 액세스 기술의 독자적인 에외를 범용적인 예외로 변홤함으로써 예외를 핸들링하는 클래스가 데이터 액세스 기술에 의존하지 않아도 된다.
범용 데이터 액세스 에외의 모든 클래스는 DataAccessException 클래스가 슈퍼 클래스이다.
| 예외 클래스 | 에러의 원인 |
|---|---|
| BadSqlGrammarException | SQL 문법 에러 |
| CanntoAcquireLockException | Lock 취득 실패 |
| ConcurrencyFailureException | 동시 실행 에러 |
| DataAccessResourceFailureException | 데이터 소스에 접속 실패 |
| DataIntegrityViolationException | 접합성 위반 에러 |
| DeadlockLoserDataAccessException | 교착 상태 발생 |
| DuplicateKeyException | INSERT / UPDATE 발생 시 PK및 UK 제약 위반 |
| EmptyResultDataAccessException | 취득할 수 있는 데이터가 없음 |
| IncorrectResultSizeDataAccessException | 취득한 레코드의 수가 부정확(1건 취득될 것이 0건이나 2건 이상이 취득) |
| OptimisticLockingFailureException | 낙관적 lock 실패 |
| PermissionDeniedDataAccessException | 권한 에러 |
범용 데이터 엑세스 예외는 실행할 때의 예외이므로 예외를 핸들링하는 쪽에서는 catch가 필수가 아니게 되고, 처리 가능한 예외만 처리 가능한 장소에서 catch하면 된다.
범용 데이터 액세스 예외의 핸들링 방침
범용 데이터 액세스 예외는 발생한 곳에서 가까운 DAO에서 catch하는 것이 되지만, DAO에 대응해야 하는 예외는 기본적으로 정의하지 않았으므로 통과되는 것으로 하고, 서비스 및 컨트롤러에서 대응해야 하는 예외만을 catch에서 처리하는 것이다. 예를 들어 교착상태에 빠져 DeadlockLoserDataAccessException에 대해서는 컨트롤러가 catch해서 브라우저에 10초 후에 재 시도해주세요라는 메세지를 표시하는 것으로 대응할 수 있다.
단, 데이터베이스에 접속되지 않는 경우에 발생하는 DataAccessResourceFailureException 등에 대해서는 서비스나 컨트롤러에서 대응할 수 있는 것이 아니므로, 공통 기능에서 catch해서 일원적으로 처리하는 것이 좋다. 예를 들어 AOP를 사용해서 관리자에게 통지하는 기능을 추가한다던지, 서블릿의 필터를 이용해서 에러페이지로 이동시키는 처리 등이 있다.
데이터 소스
데이터베이스 접속이 필요하고, 데이터베이스에 접속할 경우에는 데이터베이스 접속을 관리해주는 데이터 소스를 준비할 필요가 있다.
데이터 소스는 데이터베이스와 접속 오브젝트인 Connection 오브젝트의 팩토리라고 할 수 있다. Connection 오브젝트의 생명 주기는 데이터 소스에 맡겨지고, 보통의 업무용 애플리케이션에서는 커넥션 풀에 의해 Connection 오브젝트를 재사용한다. 무한히 Connection 오브젝트를 작성해서 리소스가 고갈되는 것을 방지하거나 Connection 오브젝트의 생성과 소멸 시의 부하를 줄이는 것이 주된 목적이다.
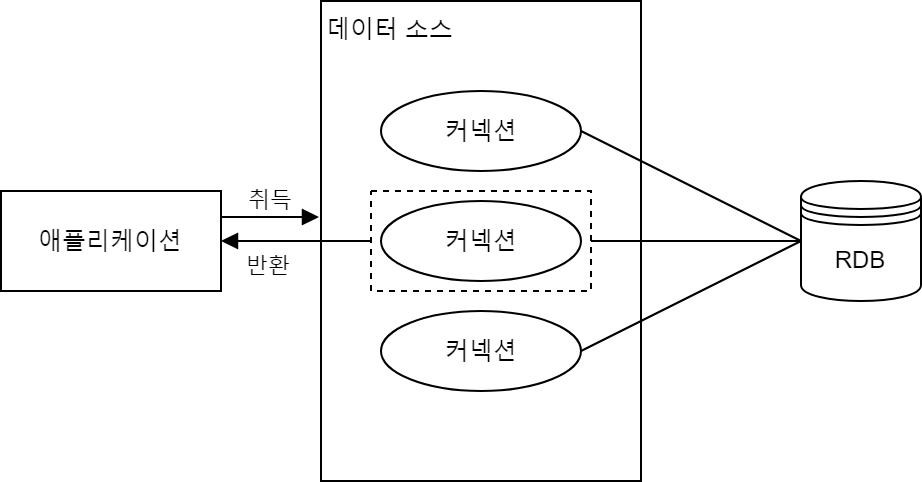
JDBC의 API로 DataSource라는 인터페이스가 제공되고, 다양한 구현 모델이 존재한다.
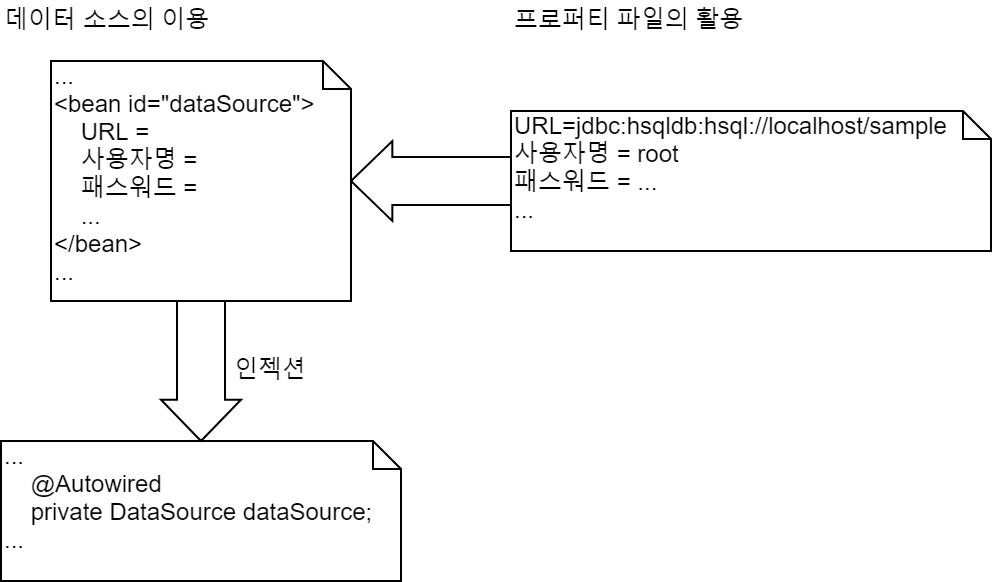
스프링에서는 데이터 소스는 우선 데이터 소스를 Bean 정의 파일이나 JavaConfig로 정의한 다음, 개발자가 작성한 Bean 등에 인젝션해서 사용한다. 인젝션할 때는 어노테이션으로 해도 되고 Bean 정의 파일이나 JavaConfig로 해도 문제가 없다.
또한, 데이터 소스를 정의할 때 지정하는 JDBC 드라이버의 이름과 URL 등의 접속 정보는 언제든 변경할 수 있게 별도의 프로퍼티 파일에 작성하는 것이 좋다. context 스키마의 property-placeholder 태그를 이용하거나, JavaConfig의 @PropertySource 어노테이션을 사용하면 프로퍼티 파일에 작성한 문자열을 Bean 정의로 이용할 수 있다.
개발자가 적절한 데이터 소스의 구현체를 선택해서 설정한다. 구현의 종류는 다음과 같이 분류할 수 있다.
서드 파티가 제공하는 데이터 소스
대표적으로 Apache Commons DBCP가 있다. 오픈 소스로, 무상으로 이용할 수 있고 커넥션 풀도 대응한다. 다음과 같이 정의할 수 있다.
<bean id="dataSource" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close"> <property name="driverClassName" value="${jdbc.driverClassName}" /> <property name="url" value="${jdbc.url}" /> <property name="username" value="${jdbc.username}" /> <property name="password" value="${jdbc.password}" /> <property name="maxTotal" value="${jdbc.maxPoolSize}" /> </bean>”${}” 내의 프로퍼티 파일을 읽기 위해 다음도 추가해주어야 한다.
<context:property-placeholder location="jdbc.properties" />property-placeholder를 지정하면 내부에서 PropertySourcesPlaceholderConfigurer 오브젝트가 생성되고 “${}” 부분에 대해서 프로퍼티값으로 치환한다.
JavaConfig로도 동일하게 정의할 수 있다.@Configuration @PropertySource("jdbc,properties") public class DataSourceConfig { @Value("${jdbc.driverClassName}") private String driverName; @Value("${jdbc.url}") private String url; @Value("${jdbc.username}") private String userName; @Value("${jdbc.password}") private String password; @Value("${jdbc.maxPoolSize}") private int maxPoolSize; // <context:property-placeholder> 태그에 해당 @Bean public static PropertySourcesPlaceholderConfigurer propertyConfig() { return new PropertySourcesPlaceholderConfigurer(); } @Bean public DataSource dataSource() { BasicDataSource dataSource = new BasicDataSource(); dataSource.setDriverClassName(driverName); dataSource.setUrl(url); dataSource.setUsername(userName); dataSource.setPassword(password); dataSource.setMaxTotal(maxPoolSize); return dataSource; } }PropertySourcesPlaceholderConfigurer를 static으로 생성하는 이유는 BeanFactoryPostProcessor를 구현하고 있는 것에서 유래한다. BeanFactoryPostProcessor는 DI 컨테이너가 가지고 있는 Bean 정의 정보를 변경하는 구조로 DI 컨테이너가 Bean의 생성을 시작하기 전에 처리된다. 따라서 static으로 생성해 정보를 변경하고 Bean을 생성해야한다.
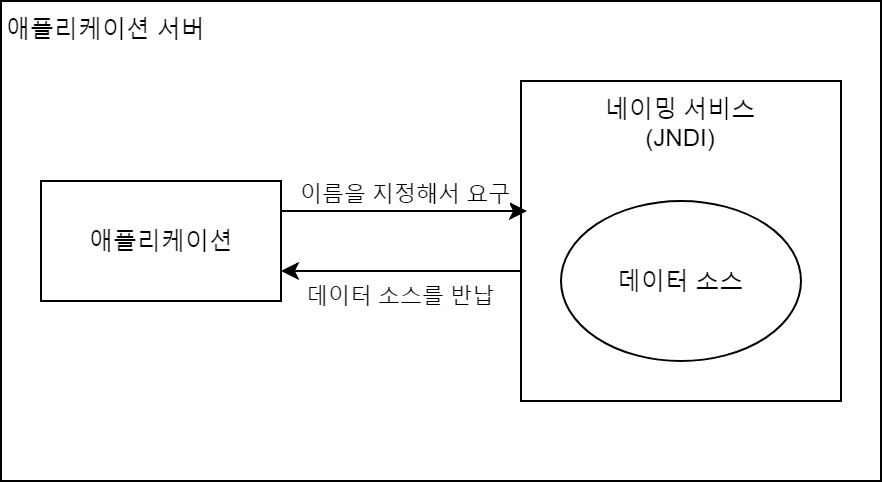
애플리케이션 서버가 제공하는 데이터 소스
일반적으로 애플리케이션 서버 제품은 데이터 소스의 오브젝트를 생성 및 관리해주는 기능이 있다. 대부분 데이터 소스 오브젝트는 애플리케이션 서버에 내장되고 네이밍 서비스로 관리된다. 네이밍 서비스가 관리하는 오브젝트에 액세스하기 위한 표준 API JNDI를 이용해 오브젝트를 취득한다.
임베디드 데이터베이스의 데이터 소스
넓은 의미로 애플리케이션과 밀접하게 결합한 데이터베이스를 이야기하지만 여기서는 애플리케이션의 자바 프로세스 위에서 작동하고 메모리상에서 데이터 관리를 하는 데이터 소스를 말한다. 제품의 라이브러리만 있으면 간단하게 이용할 수 있고 기동역시 빠르므로 테스트용 데이터베이스로 애용되고 있다.
스프링에서 지원하는 데이터베이스 제품은 다음과 같다.
- HSQLDB
- H2
- Apache Derby
스프링 JDBC
JDBC를 래핑한 API를 제공하고 JDBC보다 간결하게 사용할 수 있는 스프링의 기능이다.
JDBC를 직접 사용한 경우의 문제점
SELECT문 하나만 실행하는데에도 connection 설정부터 굉장히 많은 소스코드를 기술해야 한다. 그리고 PreparedStatement를 취득했을 때 반드시 클로즈 처리를 해야 하지만, 실수로 잊어버려 데이터베이스의 리소스 고갈과 메모리 리크의 원인이 되기도 한다.
스프링 JDBC의 이용
위의 문제는 스프링 JDBC를 활용함으로써 해결할 수 있다. JDBC를 직접 사용할 때 발생하는 장황한 코드를 숨겨주고, SQLException 처리도 필요없어진다.
Template 클래스
스프링 JDBC에 중요한 클래스 2개는 JdbcTemplate과 NamedParameterJdbcTemplate이다. JDBC를 직접 사용했을 때 생기는 장황한 처리 부분을 지정된 Template으로 구현해주는 것이다.
- JdbcTemplate
메서드의 종류가 풍부하고 직접 이용할 수 있는 JDBC의 API 범위도 넓다.- NamedParameterJdbcTemplate
SQL 파라미터에 임의의 이름을 붙여 SQL을 발행할 수 있다.
JdbcTemplate을 자주 이용하고, 이것 만으로 모든 기능을 적용할 수 있다.
템플릿 클래스의 오브젝트 생성과 인젝션
템플릿 클래스의 메서드를 사용하기 위해 오브젝트를 생성해야 한다. Bean 정의를 할 때 스프링이 오브젝트를 생성하게 하는 것이 좋다.
XML로 Bean 정의하는 경우<bean class="org.springframework.jdbc.core.Jdbctemplate"> <constructor-arg ref="dataSource" /> </bean> <bean class="org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate"> <constructor-arg ref="dataSoruce" /> </bean>
JavaConfig로 정의하는 경우@Autowired private DataSource dataSource; @Bean public JdbcTemplate jdbcTemplate() { return new JdbcTemplate(dataSource); } @Bean public NamedParameterJdbcTemplate namedParameterJdbcTemplate() { return new NamedJdbcTemplate(dataSource); }두 경우 모두 데이터소스가 어딘가에서 Bean 정의가 됐다는 전제로 한다.
SQL 발행 방법은 다음 테이블로 설명한다.
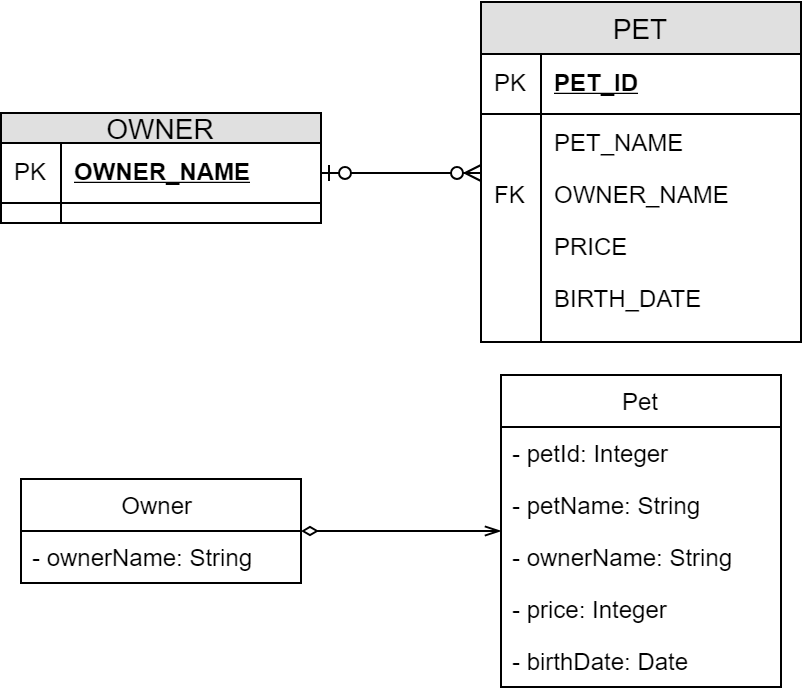
SELECT 문(도메인으로 변환하지 않을 때)
queryForObject 메서드
레코드의 건수를 취득하는 경우나, 특정 칼럼만 취득하는 등 값을 단순하게 취득하는 경우를 말한다.
int count = jdbcTemplate.queryForObject( "SELECT COUNT(*) FROM PET", Integer.class);단순 JDBC를 사용한 경우에 여러 줄로 기술해야 했던 코드를 단 한 줄로 기술할 수 있게 됐다.
Integer 뿐만 아니라 String, Date(java.util)등도 취득할 수 있다.
queryForMap 메서드
칼럼이 아니라 한 레코드의 값을 가져오는 방법이다.
Map<String, Object> pet = jdbcTemplate.queryForMap("SELECT * FROM PET WHERE PEI_ID=?", id);여기서 만약 PET_NAME 칼럼 값을 참조하고 싶다면 다음처럼 기술한다.
String petName = (String)pet.get("PET_NAME");
queryForList 메서드
여러 레코드분의 Map을 가져올 때나 칼럼들을 가져올 때 사용한다.
List<Map<String, Object>> petList = jdbcTemplate.queryForList( "SELECT * FROM PET WHERE OWNER_NAME=?", ownerName);List<Integer> priceList = jdbcTemplate.queryForList( "SELECT PRICE FROM PET WHERE OWNER_NAME=?", ownerName);
SELECT 문(도메인으로 변환할 때)
queryForObject와 query 메서드를 사용한다.
queryForOjbect
한 레코드의 도메인을 가져올 떄 사용한다.
Pet pet = jdbcTemplate.queryForObject( "SELECT * FROM PET WHERE PET ID=?", new RowMapper<Pet>() { public Pet mapRow(ResultSet resultSet, int rowNum) throws SQLException { Pet pet = new Pet(); pet.setPetId(resultSet.getInt("PET_ID")); pet.setPetName(resultSet.getString("PET_NAME")); ... return pet; } }, id );RowMapper는 스프링이 제공하는 인터페이스로, mapRow 메서드는 1건의 레코드를 도메인으로 변환해서 반환값으로 돌려주는 처리를 기술한다. 따로 MyRowMapper처럼 클래스를 만들어서 사용해도 된다.
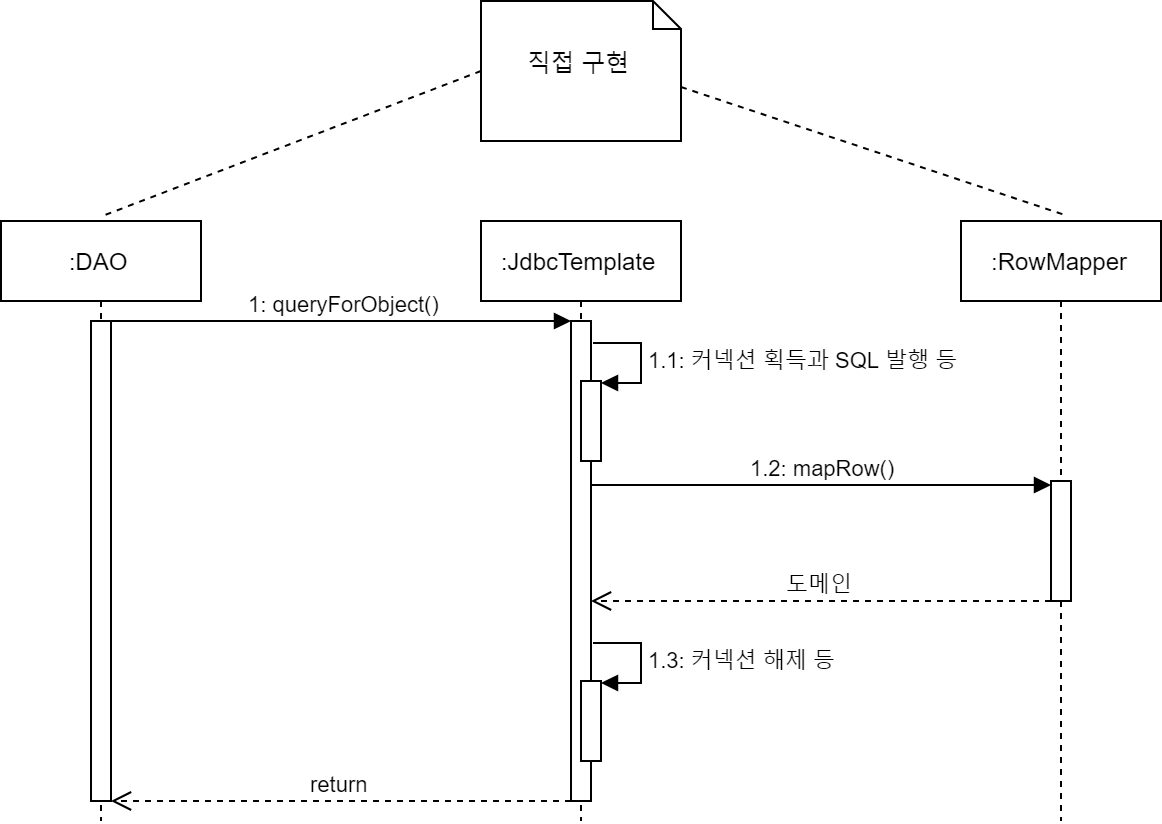
DAO가 RowMapper 오브젝트를 queryForObject 메서드의 인수로 넘기면 JdbcTemplate은 커넥션을 획득하고 SQL을 발행해서 ResultSet을 얻는다. 그 다음 ResultSet을 파라미터로 해서 mapRow를 호출한다. mapRow 내부에서 ResultSet이 도메인으로 편환된 오브젝트가 queryForObject 메서드의 반환값으로 돌아온다.
query 메서드
여러 레코드의 오브젝트를 가져오려면 query 메서드를 사용해야 한다. 사용법은 queryForObject와 동일하다.
List<Pet> pets = jdbcTemplate.query("SELECT * FROM PET WHERE OWNER_NAME=?", new PetRowMapper(), ownerName);여기서 PetRowMapper도 직접 구현하지 않고 자동으로 변환하게 해줄 수 있는데, BeanPropertyRowMapper를 사용한다.
List<Pet> pets = jdbcTemplate.query("SELECT * FROM PET WHERE OWNER_NAME=?", new BeanPropertyRowMapper<Pet>(Pet.class), ownerName);단, 컬럼의 이름과 set메서드의 이름이 같아야 한다.
ex) PET_ID -> setPetId
같지 않다면 변환되지 않는다! null이나 0이 채워진다.
매우 편리하지만 내부에서 리플렉션을 많이 사용하므로 성능이 나빠진다.
테이블을 JOIN한 SELECT 문일 때, 예를 들어 OWNER 테이블의 한 레코드와 외부 키가 연결된 PET 테이블의 여러 레코드를 가져오고 싶을 때는 RowMapper 인터페이스가 적절하지 않다. 이럴 때는 ResultSetExtractor를 사용한다. 레코드 한 건에 대한 변환 처리를 하는 mapRow 메서드와 달리 extractData 메서드는 가져온 여러 레코드를 한 번에 처리할 수 있다. 사용 방법은 다음과 같다.Owner owner = jdbcTemplate.query("SELECT * FROM OWNER O INNER JOIN PET P ON O.OWNER_NAME = P.OWNER_NAME WHERE O.OWNER_NAME=?", new ResultSetExtractor<Owner>() { @Override public Owner extractData(ResultSet resultSet) throws SQLException, DataAccessException { if (!resultSet.next()) { return null; } Owner owner = new Owner(); owner.setOwnerName(resultSet.getString("OWNER_NAME")); do { Pet pet = new Pet(); pet.setPetId(resultSet.getInt("PET_ID")); pet.setPetName(resultSet.getString("PET_NAME")); pet.setOwnerName(resultSet.getString("OWNER_NAME")); pet.setPrice(resultSet.getInt("PRICE")); pet.setBirthDate(resultSet.getDate("BIRTH_DATE")); owner.getPetList().add(pet); } while (resultSet.next()); return owner; } }, ownerName);만약 OWNER 테이블의 레코드를 여러 건 가져올 때는 extractData 안에서 Pet 오브젝트와 Owner 오브젝트를 적절히 연결하면서 Owner 오브젝트를 List 안에 채워 넣어 반환값으로 돌려주는 구현이 필요하다.
소스 코드가 복잡해지므로 간결하게 하고 싶다면 OWNER 테이블용 SQL과 PET 테이블용 SQL을 RowMapper를 사용해 두 번 발행한 다음 Owner 오브젝트와 Pet 오브젝트를 연결해 주는 것도 방법이다.
INSERT/UPDATE/DELETE 문
update 메서드만을 사용하므로 아주 간단하다. 이 메서드는 SQL의 UPDATE문을 뜻하지 않는다.
INSERT
jdbcTemplate.update("INSERT INTO PET (PET_ID, PET_NAME, ONWER_NAME, PRICE, BIRTH_DATE) VALUES (?, ?, ?, ?, ?)", pet.getPetId(), pet.getPetName(), pet.getOwnerName(), pet.getPrice(), price.getBirthDate());
NamedParameterJdbcTemplate
지금까지 SQL의 파라미터에 플레이스홀더(? 마크)를 사용해서 지정했다. 순서를 맞추어 주어야 하는데 플레이스홀더의 값이 많아지면 순서가 어긋나 엉뚱한 값을 지정할 수도 있다. 이럴 때 NamedParameterJdbcTemplate클래스를 사용하여 파라미터에 이름을 설정하여 이름과 값을 명시적으로 연결할 수 있다.
소스코드
배치 업데이트, 프로시저콜
batchUpdate 메서드
여러 개의 갱신(UPDATE, INSERT 문의 실행)을 모아서 데이터베이스에서 처리하기 위한 것이다. 하나씩 실행하는 것과 비교하면 성능에서 큰 차이가 있으므로 갱신하는 양이 많은 경우에 배치 업데이트를 사용하는 것이 좋다.
첫 번째는 BatchPareparedStatementSetter 클래스의 익명 클래스의 오브젝트를 인수로 넘겨주는 방법이다.ArrayList<Pet> petList = ... // 갱신할 Pet 오브젝트들 준비 int[] num = jdbcTemplate.batchUpdate( "UPDATE PET SET OWNER_NAME=? WHERE PET_ID=?", new BatchPreparedStatementSetter() { @Override public void setValues(PreparedStatement ps, int i) thros SQLException { ps.setString(1, petList.get(i).getOwnerName()); ps.setInt(2, petList.get(i).getPetId()); } @Override public void getBatchSize() { return petList.size(); } });두 번째는 NamedParameterJdbcTemplate의 batchUpdate 메서드를 사용한다.
SqlParameterSource[] batch = SqlParameterSourceUtils.createBatch(petList.toArray()); num = namedParameterJdbctemplate.batchUpdate( "UPDATE PET SET OWNER_NAME=:ownerName WHERE PET_ID=:petId", batch);프로시저콜
데이터베이스에 준비된 스토어드 프로시저를 호출할 때 사용하는 것이다. 스프링 2.5부터 제공된 가장 단순한 방법인 SimpleJdbcCall을 사용하는 방법이다.
호출하고 싶은 스토어드 프로시저를 다음과 같이 정의한다.
- 프로시저 이름: CALC_PET_PRICE
- IN 파라미터: IN_PET_ID
- OUT 파라미터: OUT_PRICE
```sql CREATE PROCEDURE CALC_PET_PRICE(IN IN_PET_ID INT, OUT OUT_PRICE INT) READS SQL DATA BEGIN ATOMIC DECLARE genka INT; SET (genka) = (SELECT PRICE FROM PET WHERE PET_ID=IN_PET_ID); SET (OUT_PRICE) = (genka * 1.08); END /프로시저콜 사용
SimpleJdbcCall call = new SimpleJdbcCall(jdbcTemplate.getDataSource()) .withProcedureName("CALC_PET_PRICE") // HSQLDB는 프로시저의 파리미터 등 메타 데이터 취득을 스프링이 지원하지 않아서 기술함 .withoutProcedureColumnMetaDataAccess() .declareParameters( new SqlParameter("IN_PET_ID", Types.INTEGER), new SqlOutParameter("OUT_PRICE", Types.INTEGER) ); // ------------------------------ MapSqlParameterSource in = new MapSqlParameterSource().addValue("IN_PET_ID", id); Map<String, Object> out = call.execute(in); int price = (int) out.get("OUT_PRICE");Oracle이나 SQL서버 등에서는 메타 데이터 취득을 스프링이 지원한다.
Spring Data JPA
Spring Data JPA를 이용한 JPA와의 연계를 알아본다. DAO 구현을 자동 생성하는 편리한 기능을 제공한다.
Spring Data JPA란?
Spring Data 프로덕트의 제품으로 다양한 데이터 액세스 기술을 간단하게 이용할 수 있게 하는 것이 목적인 프로덕트이다. Spring Data JPA의 주요 특징은 DAO 구현의 자동 생성으로 CRUD 등과 같은 단순한 쿼리를 실행하는 것뿐이라면 코딩할 필요가 거의 없다.
JPA의 기초
JAVA EE에 포함된사양 중 하나로, ORM 표준화된 API를 제공한다. 하이버네이트 및 EclipseLink 등의 ORM 제품이 JPA에 대응되고 있다.
JPA를 이용한 프로그램의 작성은 기본적으로 다음 두 작업이 필요하다.
- Entity 클래스의 작성
- EntityManager 메서드 호출
Entity 클래스의 작성
예제에 사용할 JDBC를 사용할 때와 동일하다.
Pet.java@Entity public class Pet { @Id private Integer petId; private String petName; @ManyToOne @JoinColumn(name="owner_id") private Owner owner; private Integer price; private Date birthDate; ... getter setter 생략 }Owner.java
@Entity public class Owner { @Id private Integer ownerId; private String ownerName; ... getter setter 생략 }@Entity 어노테이션을 부여함으로서 영속화의 대상이 된다. @Id는 엔티티를 고유하게 식별하는 프로퍼티 즉 프라이머리 키에 부여한다. ManyToOne, ManyToMany, OneToOne, OneToMany 등 관계를 어노테이션으로 관계를 부여해 주고 @JoinColumn으로 외래 키를 지정한다.
클래스명과 테이블명의 대응, 프로퍼티명과 칼럼명의 대응은 ORM이 자동으로 연결해준다.EntityManager 메서드 호출
오브젝트 세계와 RDB 세계를 연결해주는 역할을 한다. Entity Manager를 통해서 엔티티를 취득하거나 갱신하면 내부에서 RDB에 액세스가 일어난다. EntityManager 오브젝트의 생성 및 취득을 위해선 여러 가지 설정이 필요하지만 여기서는 생략한다.
EntitiyManager 호출 예제EntitiyManager entitiyManager = ... // 취득 생략 EntityTranscation transaction = entitiyManager.getTransaction(); // 트랜잭션을 개시하는 메서드 호출 transaction.begin(); Pet pet = new Pet(); pet.setPetId(1); pet.setPetName("흰둥이"); pet.setPrice(15000); pet.setBirthDate(new SimpleDateFormat("yyyyMMdd").parse("20190101")); // persist 메서드로 새로운 엔티티 추가 entitiyManager.persist(pet); // ID를 지정해 엔티티를 취득한 후, 취득한 엔티티를 삭제 Pet pet10 = entityManager.find(Pet.class, 10); entitiyManager.remove(pet10); // ID를 지정해 취득한 엔티티의 프로퍼티를 변경함 Pet pet11 = entityManager.find(Pet.class, 11); pet11.setPetName("복실이"); // commit 메서드가 호출되야 갱신된 프로퍼티값이 데이터베이스와 동기화돼 해당하는 칼럼의 값이 갱신됨 transaction.commit(); // SQL와 비슷한 JPQL을 이용해 엔티티 검색. 테이블명과 칼럼명 이용하지 않고 클래스명과 프로퍼티명 이용 List<Pet> petList = entitiyManager.createQuery("select p from Pet p where p.price < ?1") .setParameter(1, 10000) .getResultList(); for (Pet currentPet: petList { System.out.printLn(currentPet.getPetName()); }
Spring Data JPA의 이용
Spring Data JPA를 이용하면 EntityManager의 메서드 호출 부분이 자동 생성된다. 그래서 EntityManager를 직접 이용하지 않지만 내부에서 이용되는 EntityManager의 설정은 필요하다.
EntityManager 설정
EntityManager의 설정은 EntityManagerFactory의 FactoryBean 설정에서 하는데 역시 Bean 정의 파일에서 하는 방법과 JavaConfig에서 하는 방법이 있다. JPA의 구현으로 하이버네이트를 사용하므로 하이버네이트의 설정도 포함된다.
Bean 정의 파일<!-- EntityManagerFactory의 설정 --> <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="persistenceProviderClass" value="org.hibernate.jpa.HibernatePersistenceProvider" /> <property name="packagesToScan" value="spring_jpa.sample.business.domain" /> <property name="jpaProperties"> <props> <prop key="hibernate.dialect">org.hibernate.dialect.HSQLDialect</prop> <prop key="hibernate.show_sql">true</prop> <prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop> </props> </property> </bean>Spring Data JPA는 내부에서 EntityManagerFactory를 이용해서 EntityManager를 취득한다.
LocalContainerEntityManagerFactoryBean을 사용하고 있는데, 특별한 이유가 없다면 이 Bean을 사용하는 것이 가장 좋다. 설정항목은 다음과 같다.
| 항목명 | 설명 |
|---|---|
| dataSource | Bean으로 관리할 데이터 소스를 지정 |
| persistenceProviderClass | JPA 구현 제품의 클래스를 지정. 제품별로 지정하는 클래스가 정해져 있음 ex) HibernatePersistenceProvider |
| packageToScan | Entity 클래스가 포함된 패키지를 지정 |
하이버네이트 고유 설정 항목
| 용어 | 정의 | |
|---|---|---|
| jpaproperties | hibernate.dialect | 데이터베이스의 종류를 지정 ex) hibernate.dialect.HSQLDialect |
| hibernate.show_sql | 하이버네이트가 내부에서 발생하는 SQL의 로그를 출력할 것인가에 대한 설정 | |
| hibernate.ejb.naming_strategy | 테이블명, 칼럼명과 클래스명, 프로퍼티명을 연결할 때의 규칙을 지정함. 밑줄을 사용한 테이블명과 칼럼명을 밑줄이 없는 클래스명과 프로퍼티명으로 대응할 수 있는 규칙을 지정하고 있음 ex) hibernate.cfg.ImprovedNamingStrategy |
|
상단의 테이블은 JPA 구현에 의존하지 않는 설정이고 하단의 테이블은 하이버네이트의 고유 설정이다.
DAO 구현을 자동으로 생성하는데 필요한 항목은 다음과 같다.<jdbc:repositories base-package = "spring_jpa.sample.business.service" />base-package 속성에 지정한 패키지 밑을 스프링이 스캔해서 Spring Data JPA에 대응한 인터페이스를 발견하면 구현 클래스를 자동으로 생성해준다.
JavaConfig@Configuration @EnableTransactionManagement @EnableJpaRepositories(basePackages = "spring_jpa.sample.business.service") public class JpaConfig { @Bean public LocalContainerEntityManagerFactoryBean entityManagerFactoryBean(DataSource dataSource) { HibernateJpaVendorAdapter adapter = new HibernateJpaVendorAdapter(); adapter.setShowSql(true); adapter.setDatabase(Database.HSQL); Properties properties = new Properties(); properties.setProperty("hibernate.ejb.naming_strategy","org.hibernate.cfg.ImprovedNamingStrategy"); LocalContainerEntityManagerFactoryBean entityManagerFactoryBean = new LocalContainerEntityManagerFactoryBean(); entityManagerFactoryBean.setJpaVendorAdapter(adapter); entityManagerFactoryBean.setJpaProperties(properties); entityManagerFactoryBean.setDataSource(dataSource); entityManagerFactoryBean.setPackagesToScan("spring_jpa.sample.business.domain"); return entityManagerFactoryBean; } @Bean public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) { return new JpaTransactionManager(entityManagerFactory); } }
DAO 인터페이스 작성
매우 간단하다. JpaRepository 인터페이스를 상속하면서 해당 Domain과 ID의 타입을 지정해주면 된다.
@Repository public interface PetDao extends JpaRepository<Pet, Integer> { }JpaRepository 외에도 사용할 수 있는 인터페이스가 많지만 이 인터페이스가 제공하는 기능이 가장 많다. 이를 통해 다음과 같은 메서드들을 사용할 수 있다.
| 메서드 | 설명 |
|---|---|
| Pet save(Pet entity) | 지정한 엔티티를 저장 |
| Pet findOne(Integer id) | ID를 지정해서 엔티티를 취득 |
| List<Pet> findAll() | 모든 엔티티를 취득 |
| void delete(Pet entitiy) | 지정한 엔티티를 삭제 |
| long count() | 엔티티의 수를 취득 |
메서드의 구현이 자동으로 이루어지고 CRUD 같은 간단한 데이터 액세스가 가능해진다.
하지만 여러 조건의 검색 메서드가 필요하므로 개발자가 독자적으로 메서드를 정의(구현은 자동 생성)할 수 있다.
명명 규칙에 따른 메서드 정의
Springn Data JPA에서는 키워드라고 부르는 명명 규칙에 따른 메서드의 이름을 부여하면, 이름이 나타내는 내용에 따른 메서드의 구현을 자동 생성해주는 기능이 있다.
@Repository public interface PetDao extends JpaRepository<Pet, Integer> { List<Pet> findByPetName(String petName); }findBy 다음에 나오는 문자열을 프로퍼티명으로 하고 프로퍼티와 같은 형을 인수로 정의하면 임의의 프로퍼티로 검색할 수 있다.
Pet 명과 지정한 가격 이하의 Pet을 검색하는 경우에도 자동 생성해줄 수 있다.List<Pet> findByPetNameAndPriceLessThanEqual(String petName, int price);And, LessThanEqual은 키워드라고 부르는데, 이 밖의 키워드로 Not, Between 등이 있다.
검색에서의 JPQL 지정
테이블 조인을 해야 하는 검색 등이 있을 때 @Query 어노테이션을 사용해 JPQL을 명시적으로 지정하여 사용할 수 있다.
@Query("select p from Pet p where p.owner.ownerName = ?1") List<Pet> findByPetOwnerName(String ownerName);위는 Owner 엔티티의 필드인 ownerName을 연결하고 있다(Pet에 존재하지 않음) ? 뒤의 번호는 파라미터의 순번을 나타낸다.
물론 파라미터명을 정해줄 수 있다.@Query("select p from Pet p where p.owner.ownerName = :ownerName") List<Pet> findByOwnerName(@Param("ownerName") String ownerName);갱신에서의 JQPL 지정
@Query와 @Modifying을 지정한다.
@Modifying @Query("update Pet p set p.price = ?1 where p.petName = ?2") int updatePetPrice(Integer price, String petName);
커스텀 구현을 하는 경우
Spring Data JPA에서는 필요한 경우 DAO 메서드를 자신이 구현할 수 있다. 그 경우 자동 생성된 DAO가 자신이 구현안 DAO 오브젝트를 호출하는 형식이 된다.

인터페이스명과 구현 클래스명은 임의이지만, Bean의 ID는 레포지토리명(구현이 자동 생성된 인터페이스명, 첫 글자는 소문자로) + Impl로 할 필요가 있다.
커스텀 DAO 인터페이스public interface PetDaoCustom { void foo(); }커스텀 DAO 구현 클래스
public class PetDaoImpl implements PetDaoCustom { @Override public void foo() { System.out.println("foo!"); } }다음 구현이 자동으로 생성되는 인터페이스에 자신이 구현한 인터페이스를 상속한다.
인터페이스 상속@Repository public interface PetDao exstends JpaRepository<Pet, Integer>, PetDaoCustom { ... }
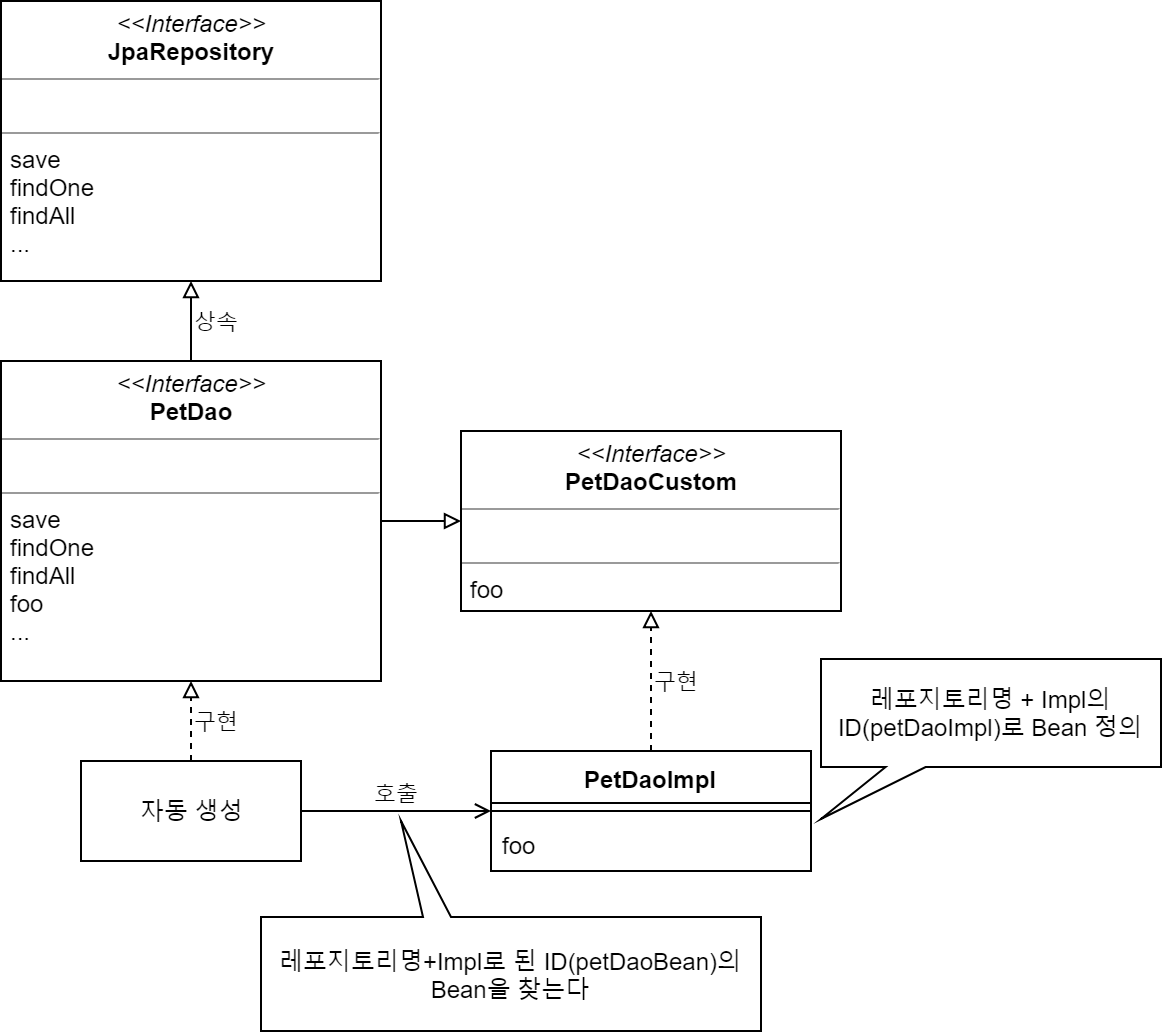
이 결과 구현이 자동 생성된 인터페이스를 통해서 자신이 구현한 DAO 메서드를 호출할 수 있게 된다.
정리
스프링을 이용하면 데이터 액세스 처리 프로그램이 간단해짐을 알 수 있다.
| tag: | spring |
|---|