
Mini-C 언어의 Lexical Analyzer 작성
27 Mar 2019 - breadkey
1. 서론
코드가 작성된 파일에서 Mini-C 언어의 어휘 문법과 일치하는 token들을 추출해내는 프로그램을 작성하였다.
symbol table, string table에 중복된 값을 등록하지 않는다.
또한 Mini-C 언어의 어휘 문법과 일치하지 않으면 해당 위치를 표시해 주고, 어휘 추출이 종료되면 추출한 token과 symbol table, string table을 출력한다.
2. 문제 분석
2.1 Mini-C언어의 token의 종류
2.1.1 Keywords
int, double, str, if, while, return, print는 각각의 type을 가진 token으로 나눈다. 여기서의 double은 숫자 DOUBLE과 겹치므로 type을 DUB이라고 정의 하였다.
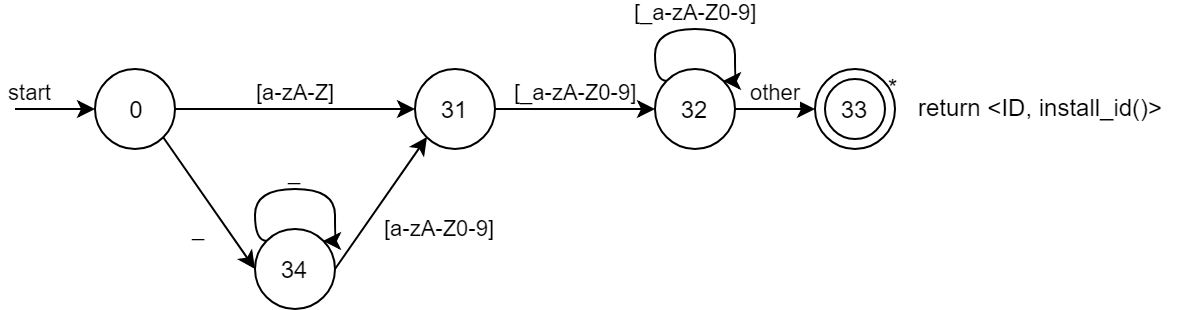
2.1.2 ID
value에 해당 id가 symbol table의 어디에 위치해있는지를 담고 있는 token이 된다.
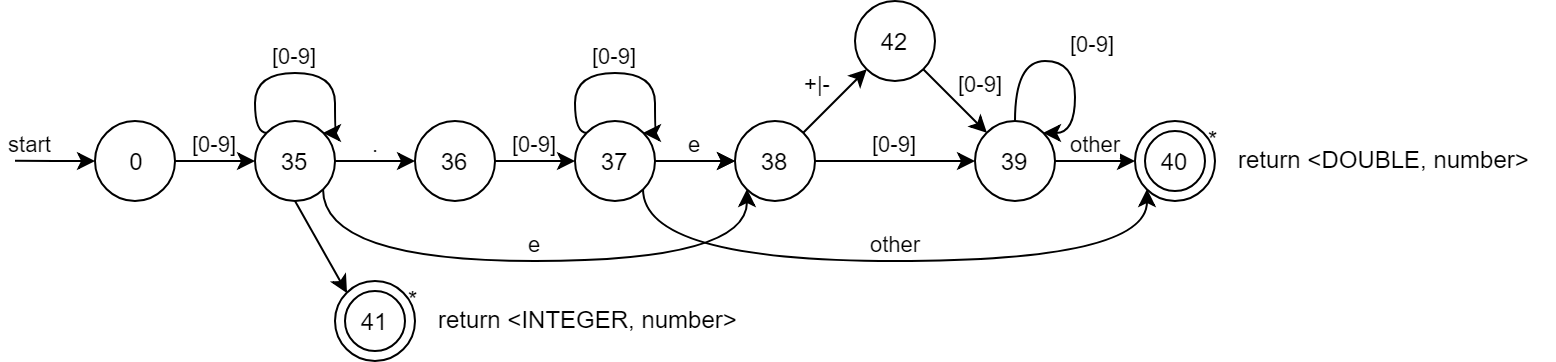
2.1.3 INTEGER
십진수를 사용하고 값을 value에 담고 있는 token이 된다.
2.1.4 DOUBLE
INTEGER와 마찬가지로 값을 value에 담고 있는 token이 되며 INTEGER 토큰과 구분해야 한다.
1.234e+5와 같이 표현될 수도 있다.
2.1.5 STRING
“에서부터 시작해 “를 만나면 읽은 값을 Java처럼 table에 저장하고 위치를 token의 value에 저장해 놓는다.
2.1.6 Operators
계산 연산에 사용되는 +, -, *, /, %는 CALOP, 할당에 사용되는 =는 ASSOP, 비교 연산에 사용되는 <. <=, ==, >=, >, !=는 RELOP으로 나눈다. value로 각 연산의 의미를 담는다.
2.1.7 기타 특수 문자들
keyword와 마찬가지로 각각의 type을 가진 token으로 나눈다.
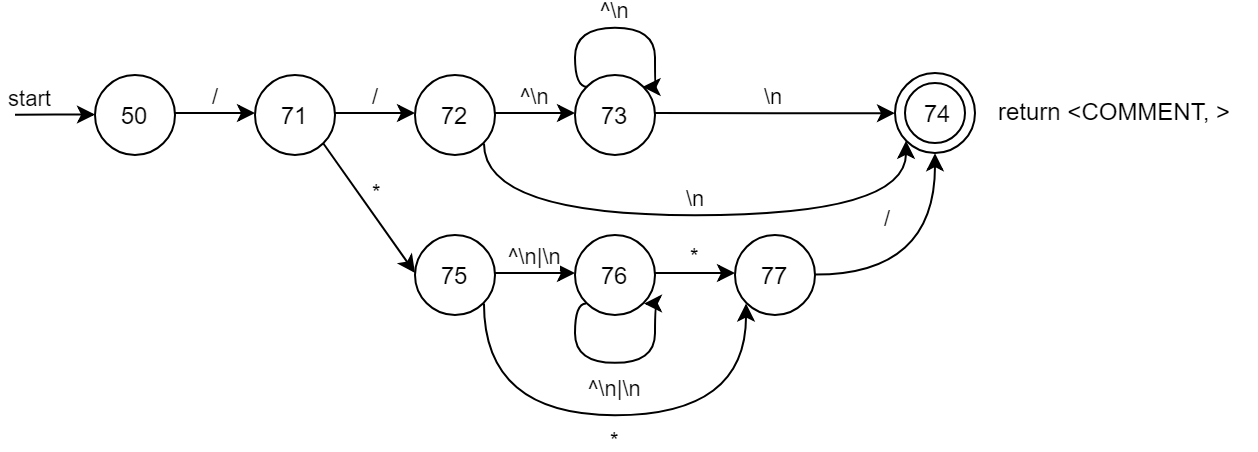
2.1.8 COMMENT
주석으로서 c언어의 //, /* */를 따른다.
2.2 translation diagram
2.2.1 Keywords
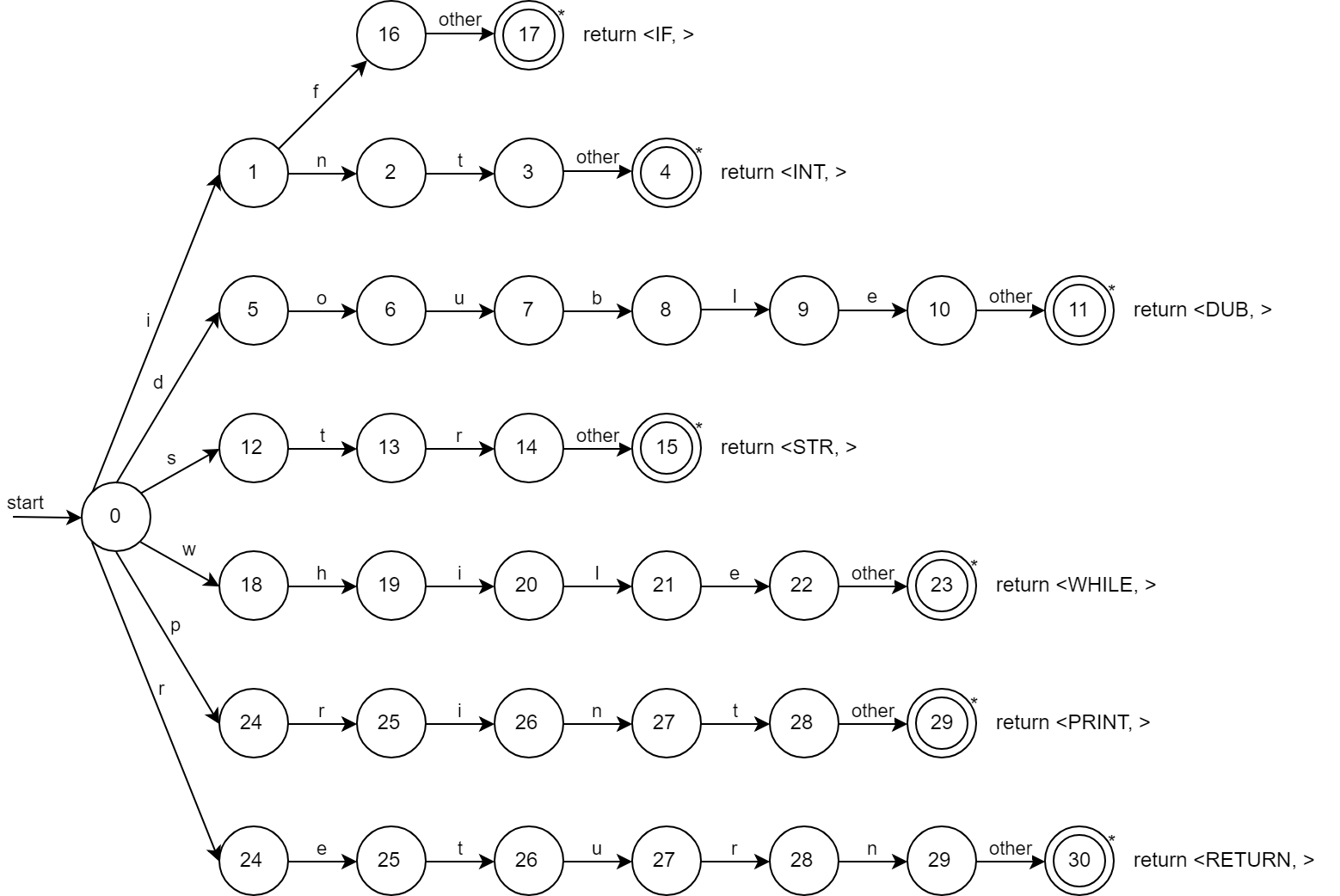
2.2.2 ID
2.2.3 INTEGER, DOUBLE
2.2.4 STRING

2.2.5 Operators
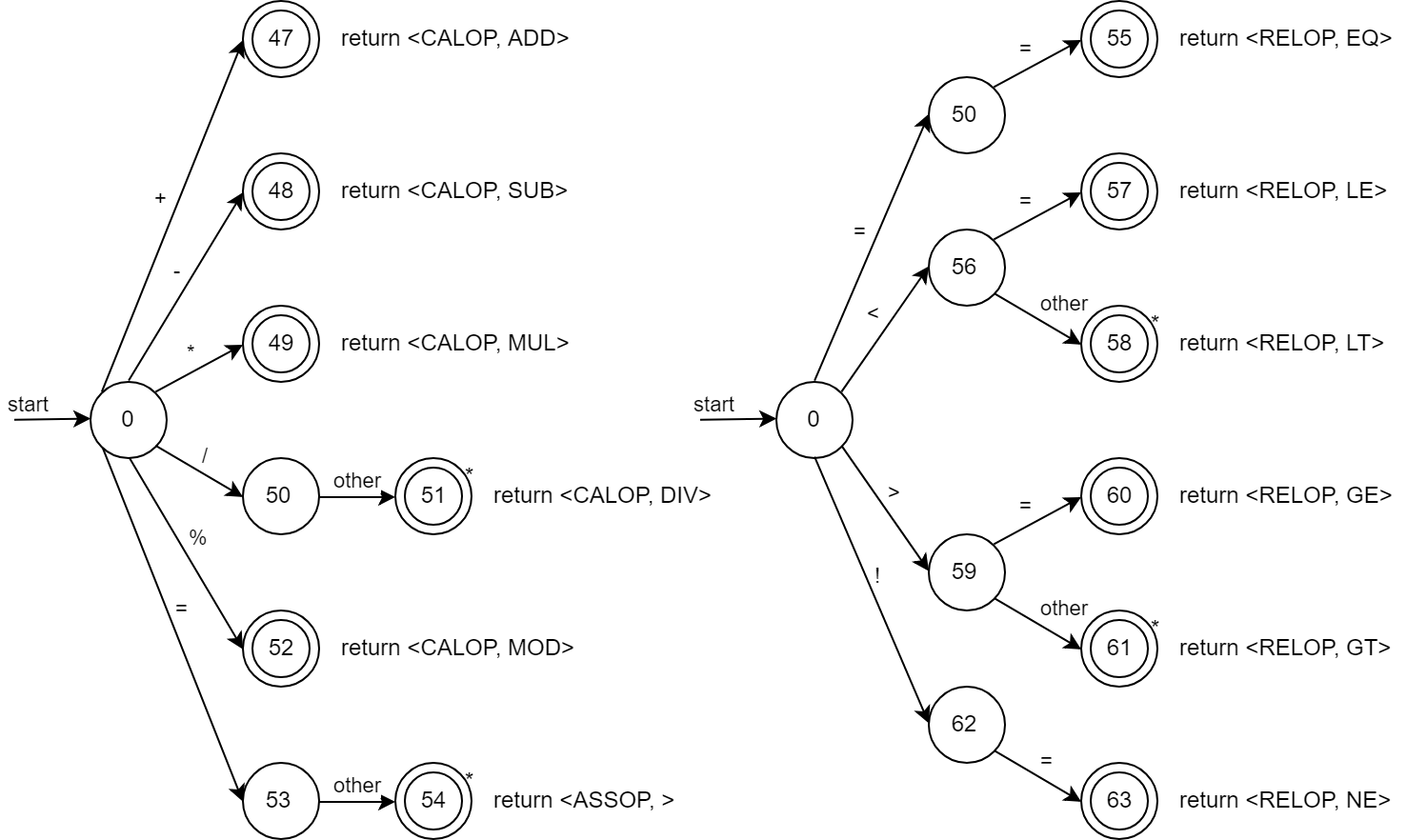
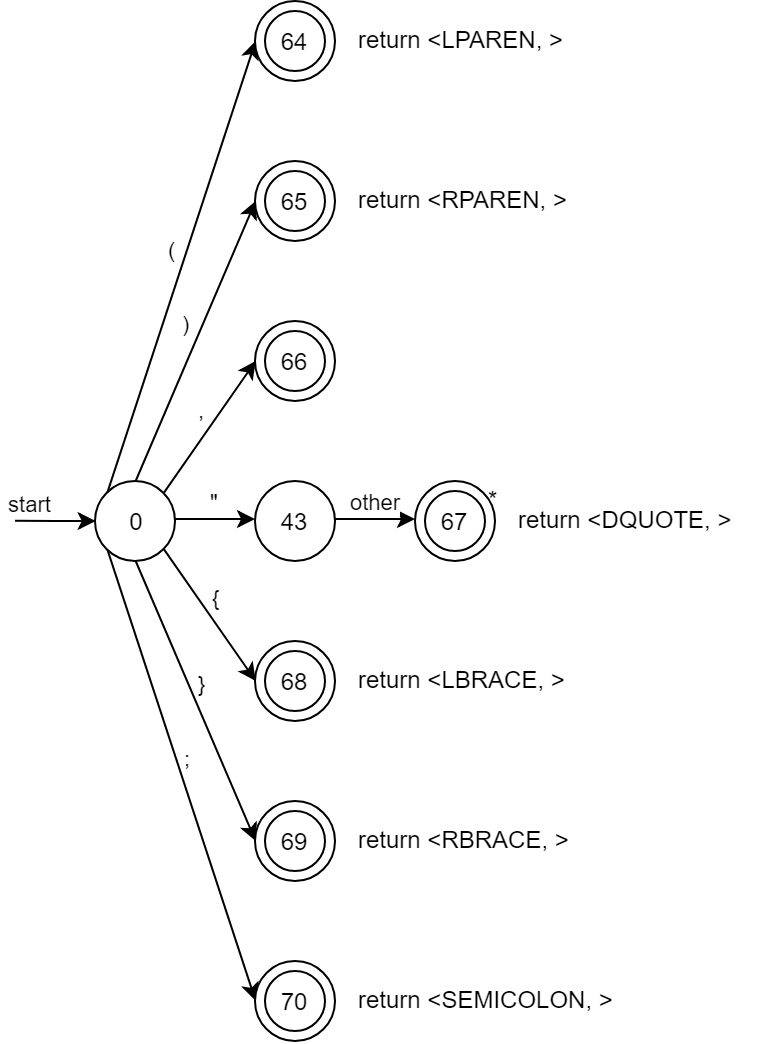
2.2.6 기타 특수 문자들
2.2.7 COMMENT
2.3 각 토큰을 위한 regular expression
| Token | Regular Expression | 비고 |
|---|---|---|
| INT | int | |
| DUB | double | |
| STR | str | |
| IF | if | |
| WHILE | while | |
| RETURN | return | |
| ID | ([a-zA-Z] | (_+[a-zA-Z0-9]))[_a-zA-Z0-9]* | _만으로는 ID가 될 수 없다(___ 등) |
| INTEGER | [0-9]+ | |
| DOUBLE | {INTEGER}("."{INTEGER})?((e("+"|"-")?)({INTEGER}))? | |
| STRING | \"[^\n^\t]*\" | 스트링 안에 \n이나 \t가 들어가면 오류이므로 이를 제외한 모든 문자가 들어갈 수 있다. |
| CALOP | "+"|"-"|"*"|"/"|% | 각각 ADD SUB MUL DIV MOD value를 가진다. |
| ASSOP | = | |
| RELOP | <|<=|==|>=|>|!= | 각각 LT, LE, EQ, GE, GT, NE value를 가진다. |
| 기타 특수문자 | \", "(", ")", "{", "}", ",", ;, | 각각 DQUOTE, LPAREN RPAREN LBRACE RBRACE COMMA SEMICOLON type을 가진다 |
| COMMENT | ("/""*"(.|\n)*"*""/")|("/""/".*\n) |
3. 설계
3.1 중요 자료구조
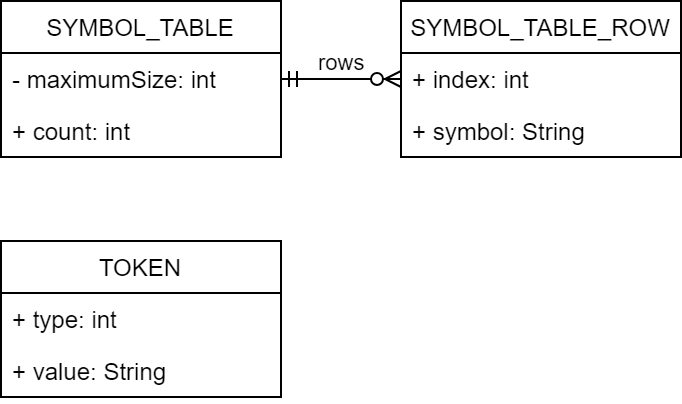
SYMBOL_TABLE은 symbol table, string table에 사용된다.
3.2 모듈구조 및 설명
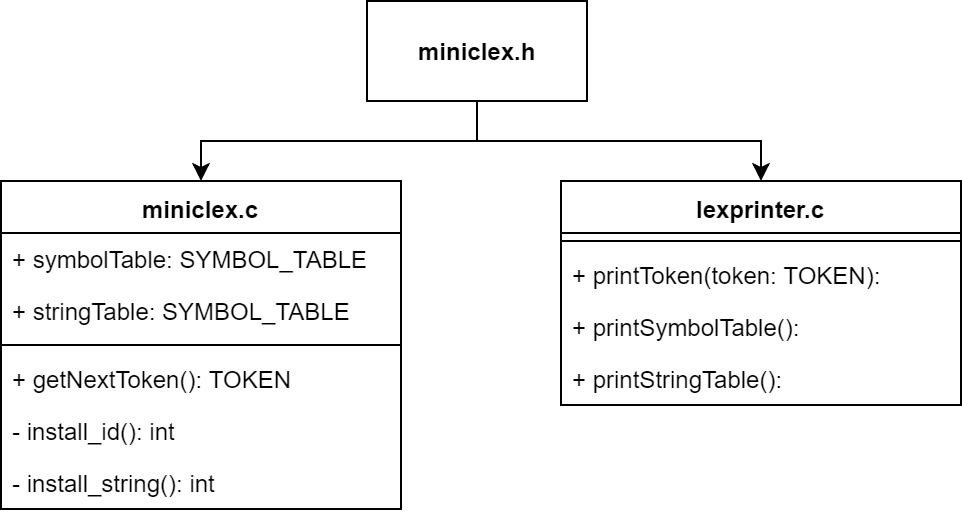
+는 헤더에 정의한 변수와 함수들이다. -는 각 모듈에서만 정의하고 사용하지만 중요한 기능을 하는 것 들이다.
3.2.1 miniclex.c
새로운 TOKEN을 생성한다.
symbolTable, stringTable을 초기화 하고 TOKEN을 생성할 때 ID나 STRING이면 각각 테이블에 추가한다.
3.2.1.1 TOKEN getNextToken()
새로운 TOKEN을 생성해 낸다.
-
- ID
- install_id()함수를 통해 symbolTable에 저장한다.
-
- INTEGER
- 최대 10자리(하위)만 저장한다.
-
- STRING
- install_string()함수를 통해 stringTable에 저장한다.
3.2.1.2 install_id(): int
ID의 value를 symbolTable에 저장하고 행의 index값을 return한다.
중복된 값이 테이블에 저장되 있으면 해당 행의 index값을 return한다.
3.2.1.3 install_string(): int
STRING의 value를 stringTable에 저장하고 행의 index값을 return한다.
값을 저장할 때 “는 제외하고 저장한다.
중복된 값이 테이블에 저장되 있으면 해당 행의 index값을 return한다.
3.2.2 lexprinter.c
TOKEN, SYMBOL_TABLE 값을 출력하는 모듈이다.
3.2.2.1 printToken(TOKEN token)
token의 값을 출력한다.
3.2.2.2 printSymbolTable();
symbolTable의 값을 출력한다.
3.2.2.3 printStringTable()
stringTable의 값을 출력한다.
4. 입력 데이터
4.1 ex1.txt
어휘 오류가 존재하지 않는 입력 데이터이다.
int f (int a, double b) {
int sum = 0;
str string = "Hello, World!"; // hello world!
while (1) {
sum += a + b;
print(a, b, sum);
int length = strlen(string);
if (sum > length) {
return 1;
}
if (sum <= 0) {
return -1;
}
if (sum == length) {
return 0;
}
if (b < 0.543125) {
b = 124124.123e+5;
}
/*
return -1;
*/
}
}
4.2 ex2.txt
어휘 오류가 존재하는 입력 데이터이다.
print(aaa,
aaa,
~, //lexcial error
aaa,
_, // lexcial error
a0123,
_asd,
_1,
_a_,
asdasf,
a112,
aaa,
a989,
basds,
bbb,
bbbb,
cascasdc,
cscacacs,
qw,
"good",
"invalie
enter",
^.^, // lexcial error
bbb,
aaa,
aldfk,
kqemfkqewmf,
nj,
fmkqn,
kowqker,
e39i3e,
_asdadod,
asdmkasmdqwl,
__asdmkin,
aaa,
would_be_error, ___, // lexical error
kiiiiji);
5. 결과 데이터
5.1 ex1.txt
5.1.1 토큰 리스트
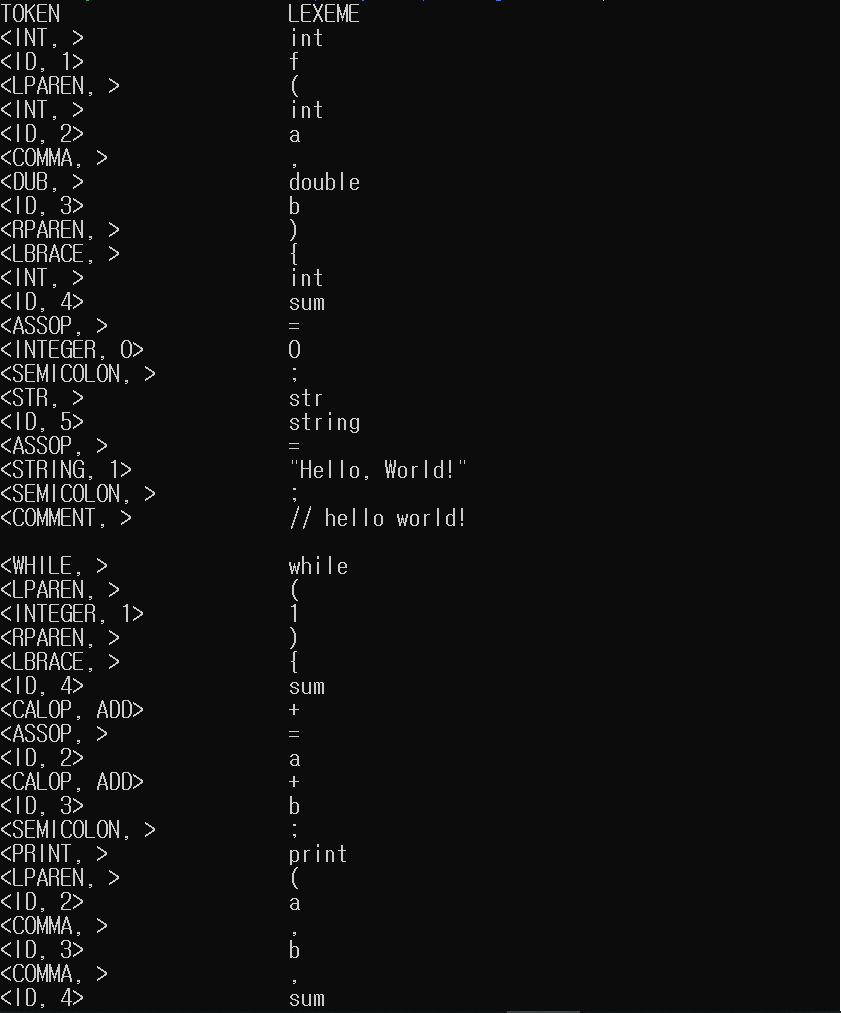
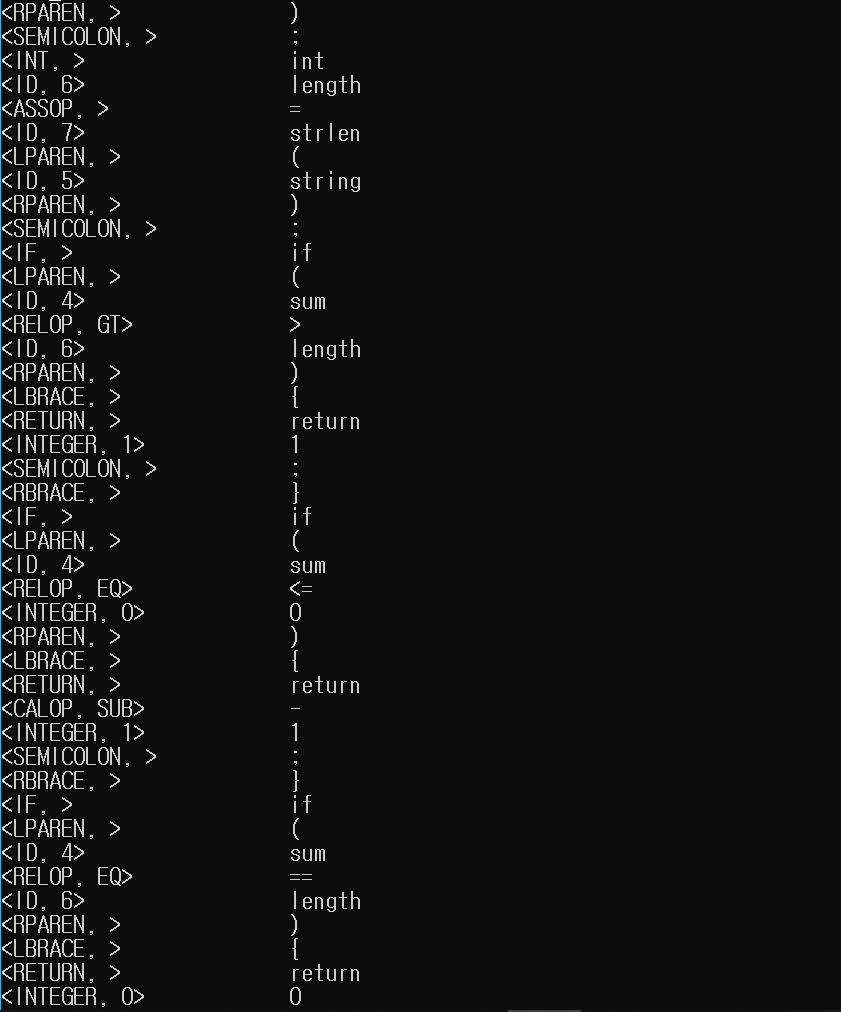
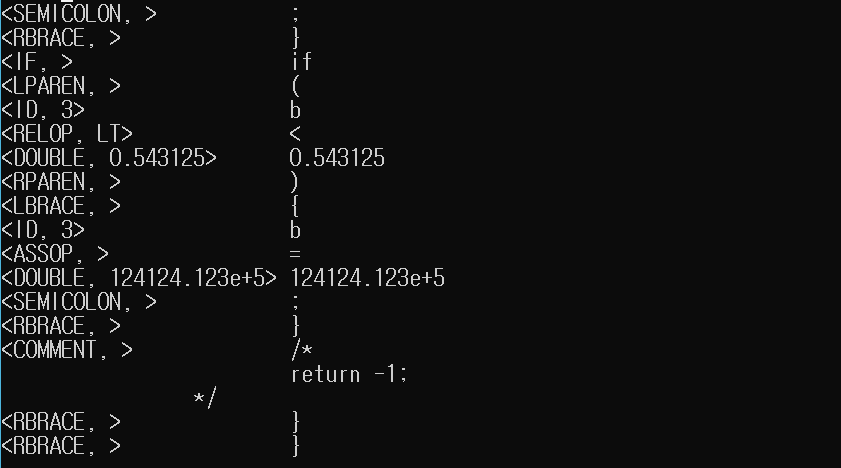
5.1.2 심볼 테이블

5.1.3 스트링 테이블
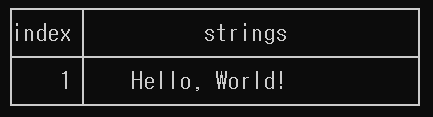
5.2 ex2.txt
5.2.1 토큰 리스트
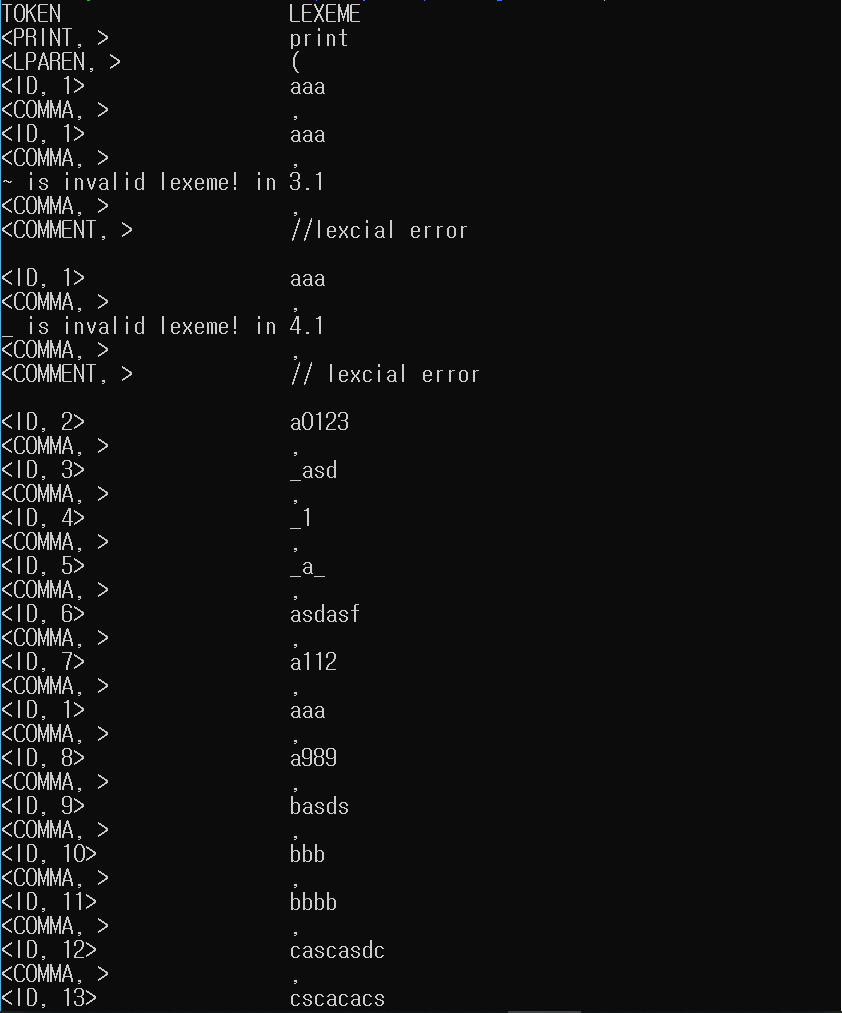
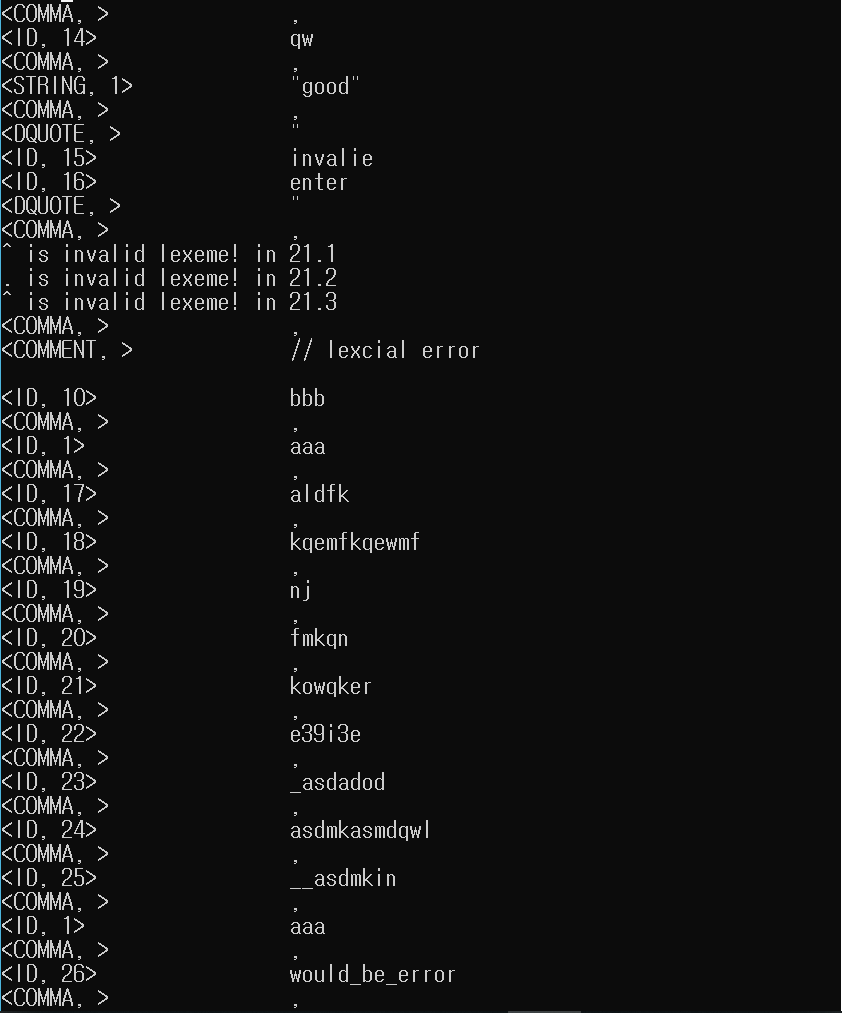
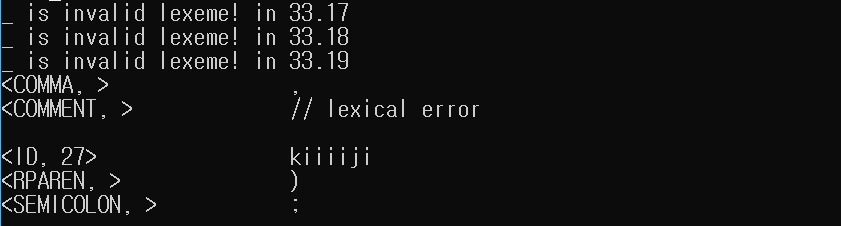
5.2.2 심볼 테이블
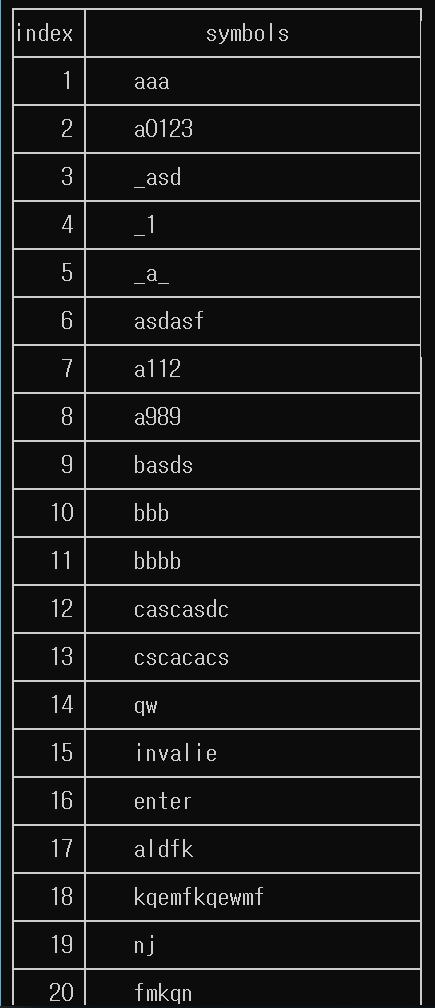
5.2.3 스트링 테이블

| tag: | compiler |
|---|